Accept: text/markdown and with .md URL variants.
Le cloud natif pour l’IApour les créateurs etAgents
Exécutez des modèles, faites évoluer les GPUs et créez des agents IA, le tout sur une seule plateforme.
Approuvé par











Exécutez plus de 200 modèles via une seule API.
Aucune infrastructure à gérer.
Texte, image, audio, vidéo — tout serverless, tout
prêt pour la production. Vous l’appelez, nous l’exécutons. Facturé au
token, pas à l’heure.
Points de terminaison privés. Performances garanties. Pas de voisins bruyants.
Votre modèle. Votre calcul. Des ressources isolées assurent une latence constante, quel que soit le débit. Parce que la production n'a pas de budget pour les nouvelles tentatives.


Exécuter la suite de tests · pytest
Écrire le correctif · patch appliqué
Identifier le bug · pointeur nul ligne 84
Lire la base de code · src/api/routes.py
Des environnements d’exécution sécurisés et isolés. Conçus pour les agents qui font réellement des choses.
Pas un notebook. Pas un conteneur que vous configurez vous-même. Un environnement conçu spécialement où les agents s’exécutent, utilisent des outils, appellent des modèles et exécutent des tâches — proprement, de manière isolée, à chaque fois.
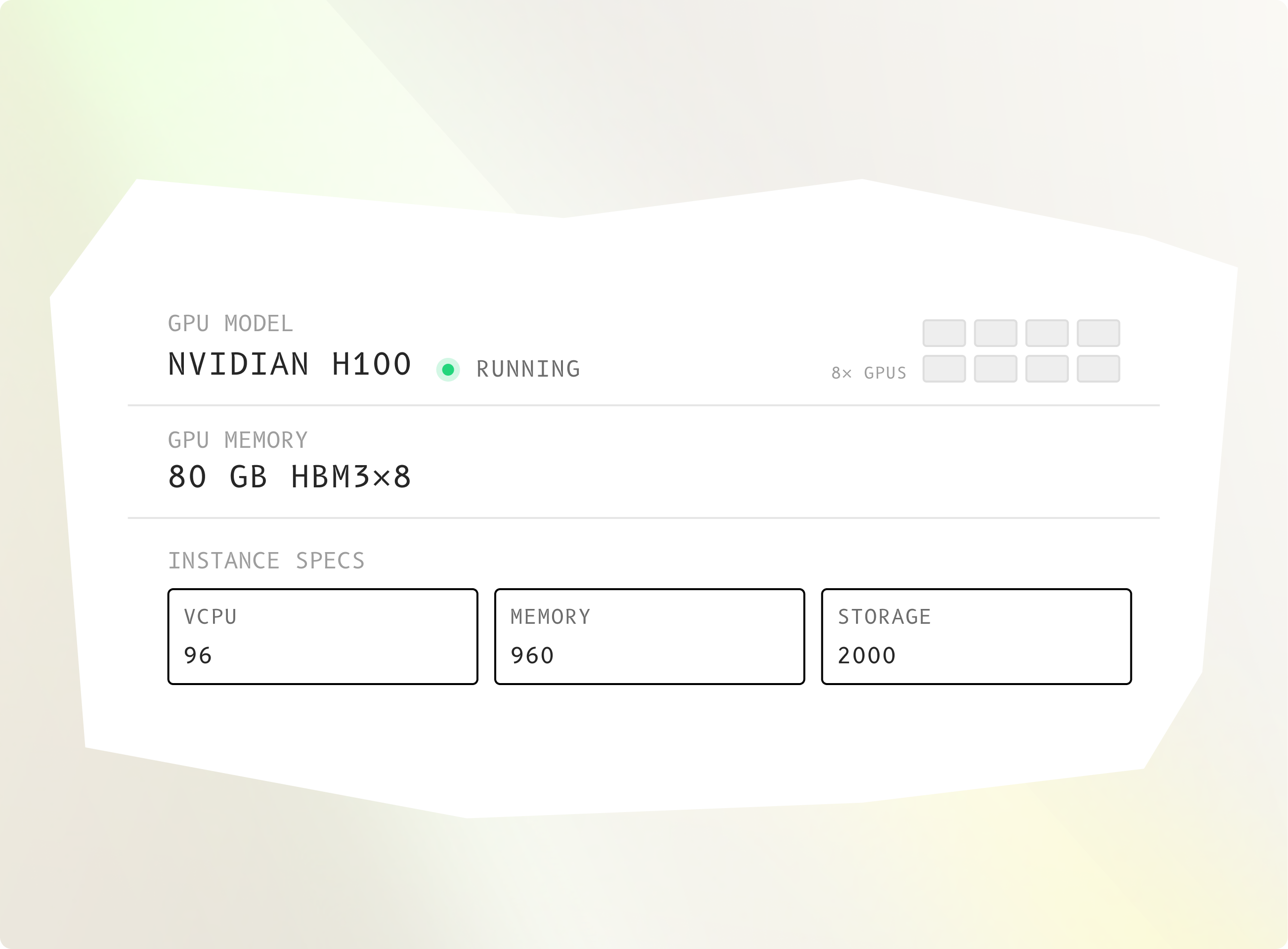
Machines GPU sous contrôle total. À vous en quelques secondes.
Déployez des modèles, exécutez l’inférence, entraînez à partir de zéro, sur des instances GPU dédiées que vous contrôlez entièrement. Des performances prévisibles. Aucune ressource partagée. Aucune surprise.
Soumettez une tâche. Nous nous occupons du reste.
Aucune instance à provisionner. Aucun calcul inactif à payer. Novita alloue automatiquement les ressources GPU, monte en charge sous forte demande et réduit à zéro lorsque vous avez terminé. Vous payez pour l’exécution, rien d’autre.

allocating gpu resources
alloué
auto
durée
0.1s
coût
$0.0001
temps d’inactivité
$0.00

Node-01
51%
Node-02
79%
Node-03
86%
Node-05
89%
Node-06
65%
Node-07
81%
GPU 8× NVIDIA H200
GPU Memory 141 GB HBM3e per GPU
Nodes 6 / 6
Interconnect NVLink 4th Gen · 900 GB/s
Network 400 Gb/s RDMA
Performances maximales. Zéro surcoût d’abstraction.
Clusters GPU physiques dédiés pour l’inférence à grande échelle, les entraînements et les déploiements d’entreprise qui ne peuvent faire aucun compromis sur le débit. Quand vous avez besoin du matériel pour vous seul, c’est la solution.
Conçu pour l’IA dès le premier jour. Pensé pour ce que vous créez réellement.
Meilleur rapport prix-performances
Jusqu’à 50 % de moins que les principaux fournisseurs cloud. Non pas parce que nous rognons sur la qualité, mais parce que nous avons construit l’infrastructure.

Conçu pour une fiabilité en production
Infrastructure stable avec faible latence, haut débit et disponibilité fiable à grande échelle.
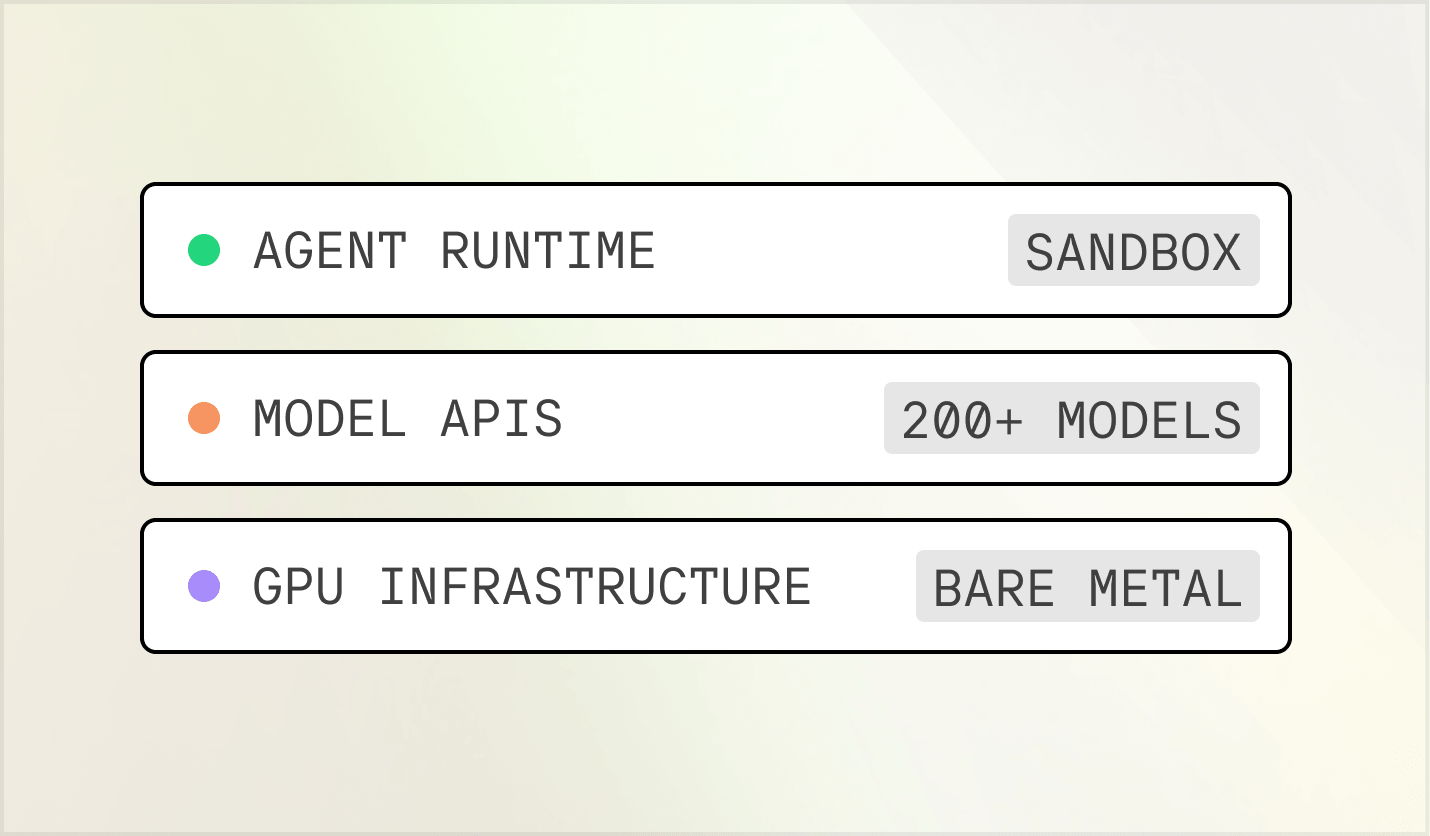
Une seule plateforme pour toute la pile IA
API de modèles, infrastructure GPU et environnements d’exécution d’agents — le tout sur une seule plateforme.
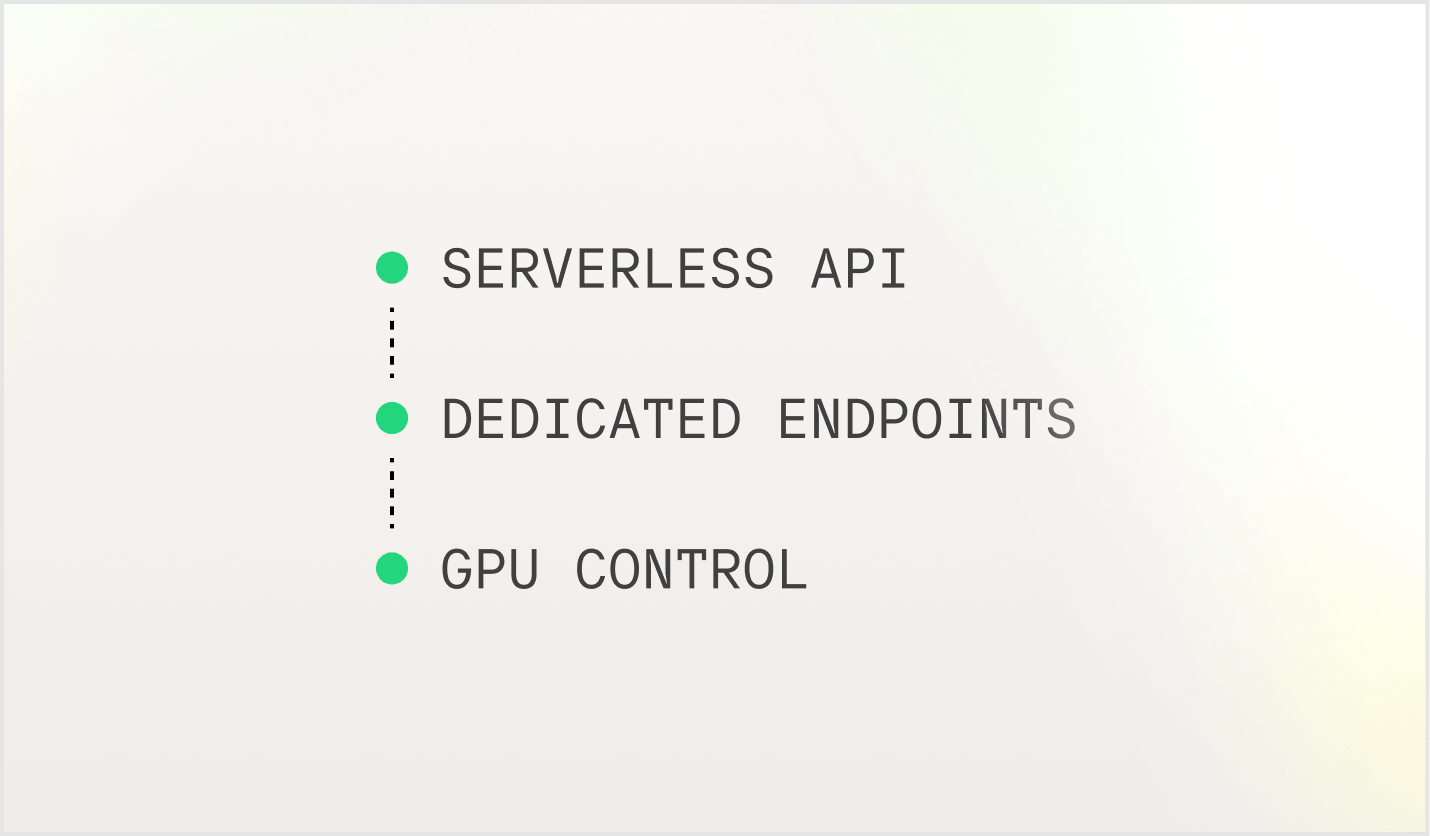
Évoluez avec votre charge de travail
Commencez petit et évoluez sans friction, des APIs aux clusters dédiés.

Assistance dédiée quand cela compte
Assistance technique rapide assurée par une équipe qui comprend l’infrastructure d’IA.

Don't take our word for it.
J’apprécie la rapidité avec laquelle Novita AI déploie les nouveaux modèles publiés. Leur équipe est souvent parmi les premières à mettre en ligne un support d’inférence stable et prêt pour la production, parfois dès le premier jour. Cette vitesse est essentielle pour toute la communauté IA open source.

Julien Chaumond
Cofondateur et CTO
Novita nous a été d'une aide précieuse chez Fish Audio. Leur infrastructure GPU fiable nous permet de nous concentrer sur le développement et l'amélioration de nos modèles de synthèse vocale, plutôt que de gérer des problèmes matériels. Leur support et leurs performances nous ont grandement facilité la progression de notre travail.

Shijia Liao
Cofondateur et directeur scientifique
L'API Model de Novita a été très simple à intégrer, et elle a été excellente pour alimenter nos flashcards et quiz propulsés par l'IA. La plateforme prend en charge le gros du travail, ce qui nous permet de nous concentrer sur la création de meilleurs outils d'apprentissage pour nos utilisateurs, sans nous soucier de l'infrastructure ou des problèmes de mise à l'échelle.

Petros Christodoulou
Cofondateur et PDG
Travailler avec Novita AI a été une expérience fantastique pour Kilo. Leur plateforme d’inférence nous aide à fournir des workflows de codage IA rapides et fiables sur plusieurs LLMs, avec de solides performances en conditions réelles pour les workflows agentiques. Et l’équipe a été remarquablement facile à contacter ! Elle optimise en permanence en fonction des derniers modèles et technologies — un partenaire idéal pour Kilo Code.

Ari Messer
Responsable des partenariats





Tout ce dont vous avez besoin pour créer une IA de production.
Plus de 200 modèles, des GPUs à la demande et des environnements d’exécution d’agents sécurisés — unifiés sous une seule API. Gratuit pour commencer, évolutif à mesure que vous grandissez.