GPU Instance
1. How to check the price of the GPU instances?
You can check the price of GPU instances and their configurations (container disk, volume disk, network volume, etc.) on the Pricing Page.2. When does the billing for GPU instance start?
Billing starts when the instance status changes to “Pulling” status.3. Introduction of container disk, volume disk, and network volume.
-
Container Disk
- Does not support dynamic expansion, can only specify capacity when creating an instance;
- Mount directory:
/(cannot be customized); - Data will be saved when saving the image;
- Supports 60GB free quota, charges will apply for the excess part, for details refer to: Billing Instructions
-
Volume Disk
- Supports dynamic expansion;
- Default mount directory:
/workspace(customizable); - Data will not be saved when saving the image;
- Read and write speed is the same as the container disk;
- Volume Disk capacity requires additional charges, for details refer to: Billing Instructions.
-
Network Volume
- Supports dynamic expansion;
- Default mount directory:
/network(customizable); - Network volume has an independent lifecycle, unrelated to the instance, even if the instance is deleted, the network volume data still exists;
- Overall read and write speed is slower than the container disk or volume disk (depending on specific usage);
- Network volume capacity requires additional charges, for details refer to: Billing Instructions
4. Why can’t the instance be restarted after it stops?
This applies to pay-as-you-go instances only. Monthly subscription instances have pre-reserved resources and will not encounter this issue.
5. How to handle abnormal instance status?
First, try to troubleshoot the problem through the “System Logs” and “Instance Logs” of the instance. If the problem cannot be resolved, you can contact us.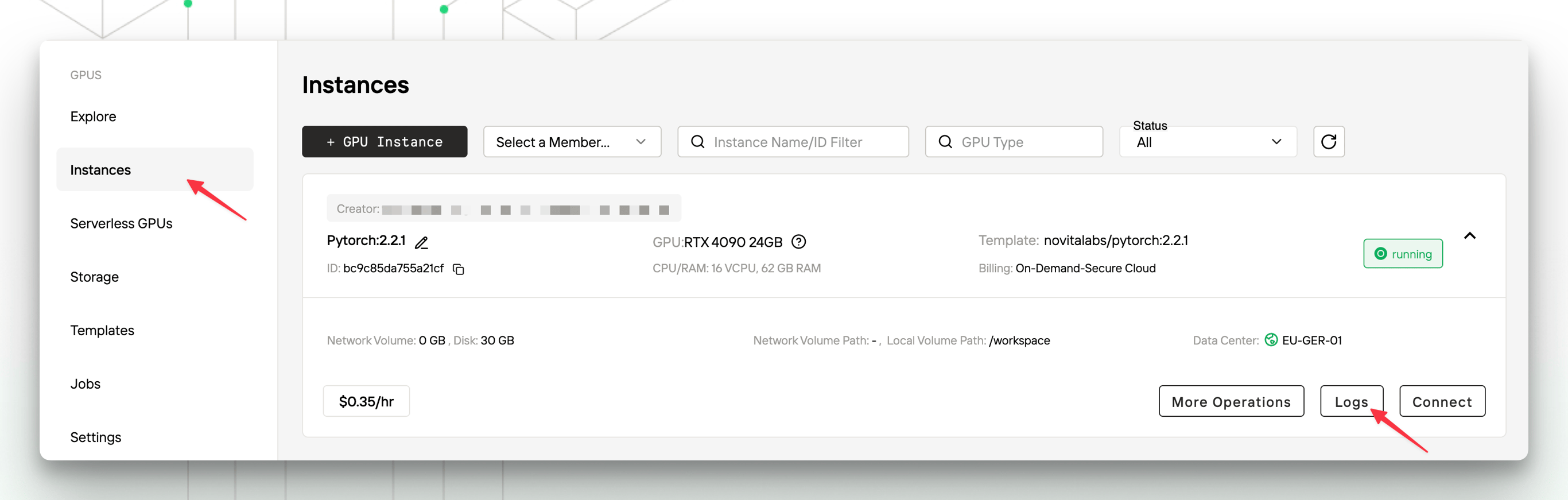
6. No instance specifications with a specified CUDA version.
CUDA versions are backward compatible. For example, if your service relies on CUDA version 12.1, you can choose an instance specification with a CUDA version greater than or equal to 12.1.7. What is the maximum CUDA version supported by the platform?
You can check the allowed CUDA versions in the “Filter” module at the bottom right corner of the Explore.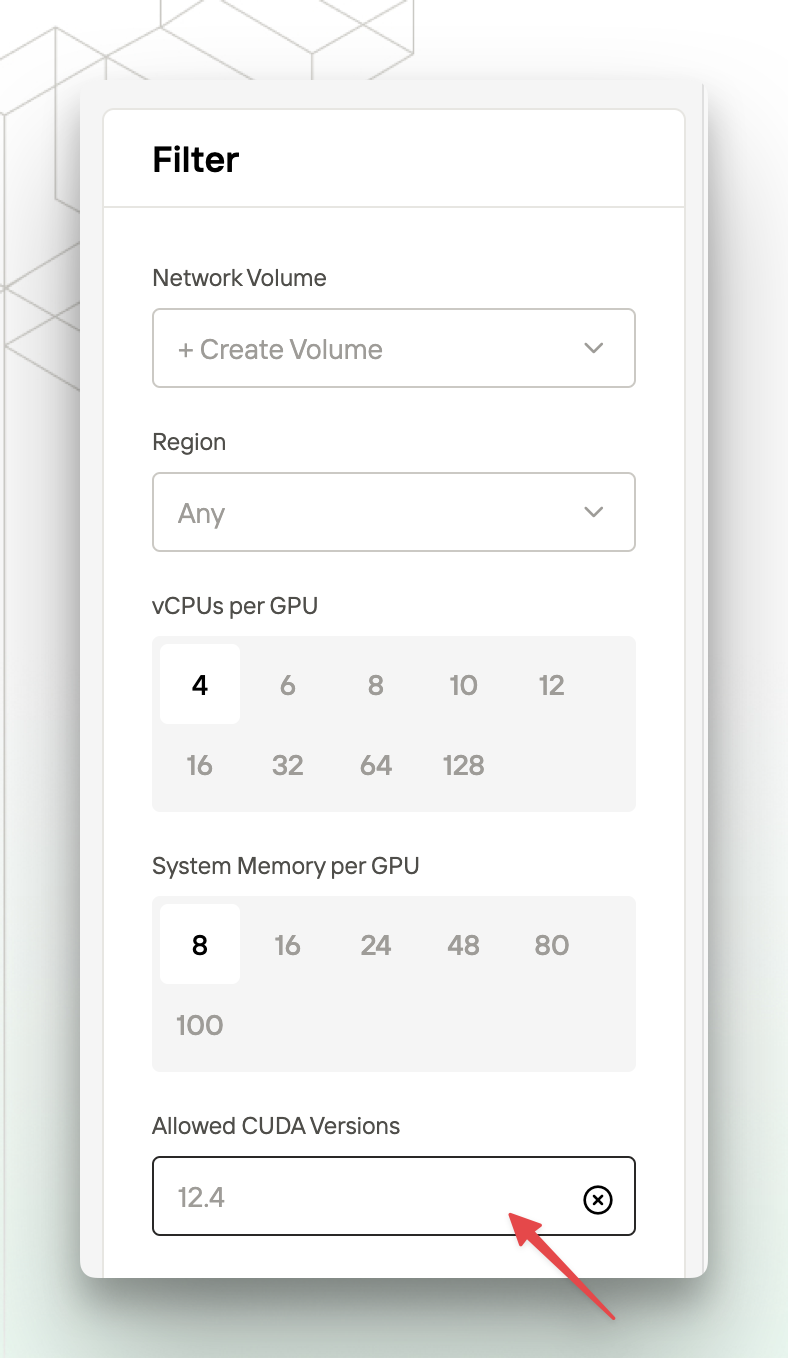
8. How to diagnose the “Save Image” failure?
First, try to troubleshoot the problem through the logs of the “Save Image” task. If you are saving the image to a private repository address, please check whether your Container Registry Auth Configuration is correct. If the problem cannot be resolved, you can contact us.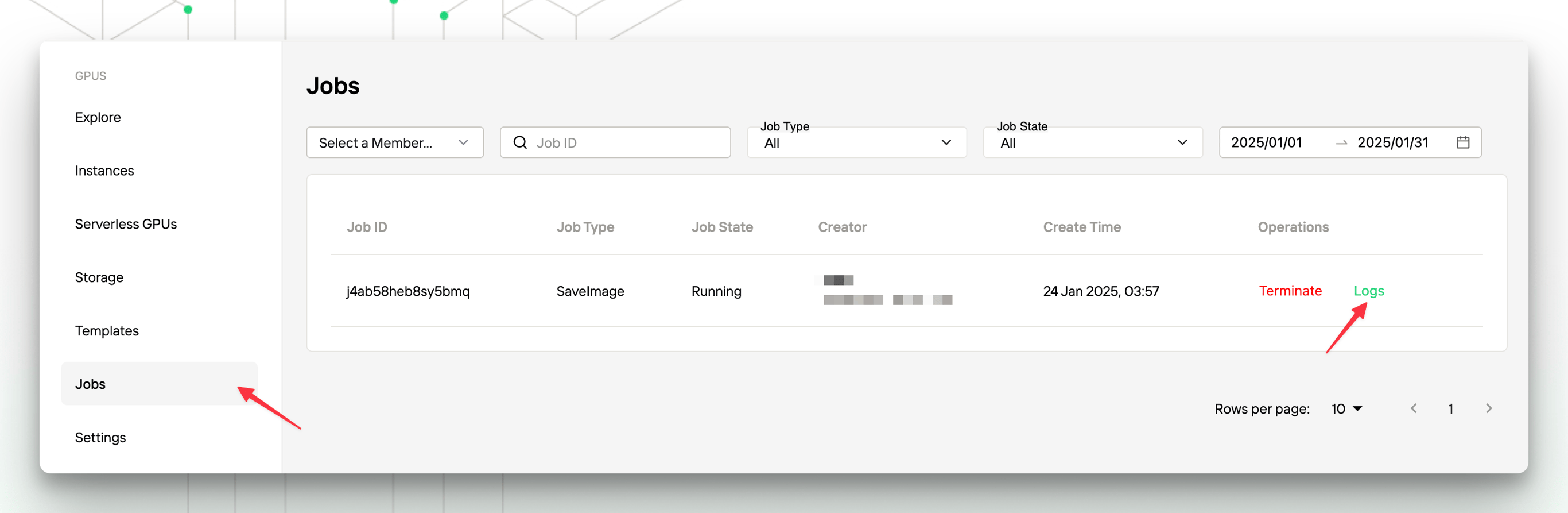
9. Can dedicated IP be supported?
Yes. Currently, this capability is not open to the public. If you have such requirements, please contact us.10. How to check the GPU usage of the instance?
Due to the PID isolation of Docker containers, thenvidia-smi command cannot be used to view the process. You can install the py3nvml library and use the shell command to check the GPU usage:
11. Can a single instance mount multiple network volumes?
Yes. Both the console and API support mounting multiple network volumes on a single instance.Serverless GPUs
1. What is the difference between Serverless GPU and GPU Instance?
Serverless GPU is designed for deploying model inference endpoints without managing infrastructure. You define an endpoint, and the platform handles scaling, scheduling, and resource allocation automatically. GPU Instance gives you a persistent, interactive VM-style environment where you manage the runtime directly. Choose Serverless GPU for production inference workloads; choose GPU Instance for development, training, or workflows requiring persistent storage and interactive access.2. How is Serverless GPU billed?
Serverless GPU is billed based on actual execution time — you are only charged when your endpoint is actively processing requests. There are no charges during idle periods. Pricing is calculated per second of GPU time consumed. For detailed rates, refer to the Serverless GPU pricing page.3. What should I do if my Serverless GPU endpoint returns a timeout error?
Timeout errors typically occur when:- The cold-start time exceeds the request timeout threshold (e.g., the container image is large and takes time to pull).
- The model inference time exceeds the configured request timeout.
- Use the image prewarm feature to reduce cold-start latency.
- Increase the request timeout setting for your endpoint if your workload requires longer processing times.
- If the issue persists, contact us with your endpoint ID and error details.
Payments
1. How can I avoid top-up failures?
Top-up failures are generally caused by two main reasons:-
Rejection from the card issuer. This may occur for the following reasons. Please check or contact your card issuer for details:
- The corresponding payment channel is not activated.
- The credit card has expired or been frozen.
- The credit card balance is insufficient.
- The card number is incorrect.
- The security code is incorrect.
-
Risk control measures from the payment channel. Please check and make any necessary adjustments:
- The device ID is associated with a high number of cards.
- The number of cards declined using this email address is very high.
- The time since this card was first seen on the Stripe network with this device ID is very short.
- The authorization rate associated with this email address is very low.
- The name on the email address does not match the name on the card.