Accept: text/markdown and with .md URL variants.
受到信赖











通过单个 API 运行 200+ 个模型。
无需管理基础设施。
文本、图像、音频、视频——全部Serverless,全部
生产就绪。您调用,我们运行。按
token 计费,而不是按小时。


运行测试套件 · pytest
编写修复 · 补丁已应用
识别错误 · 第 84 行空指针
读取代码库 · src/api/routes.py
安全、隔离的运行时。专为真正能做事的智能体而构建。
不是笔记本。也不是需要你自行配置的容器。而是一个专为智能体打造的环境,让智能体能够运行、使用工具、调用模型并执行任务——每一次都干净利落、相互隔离。
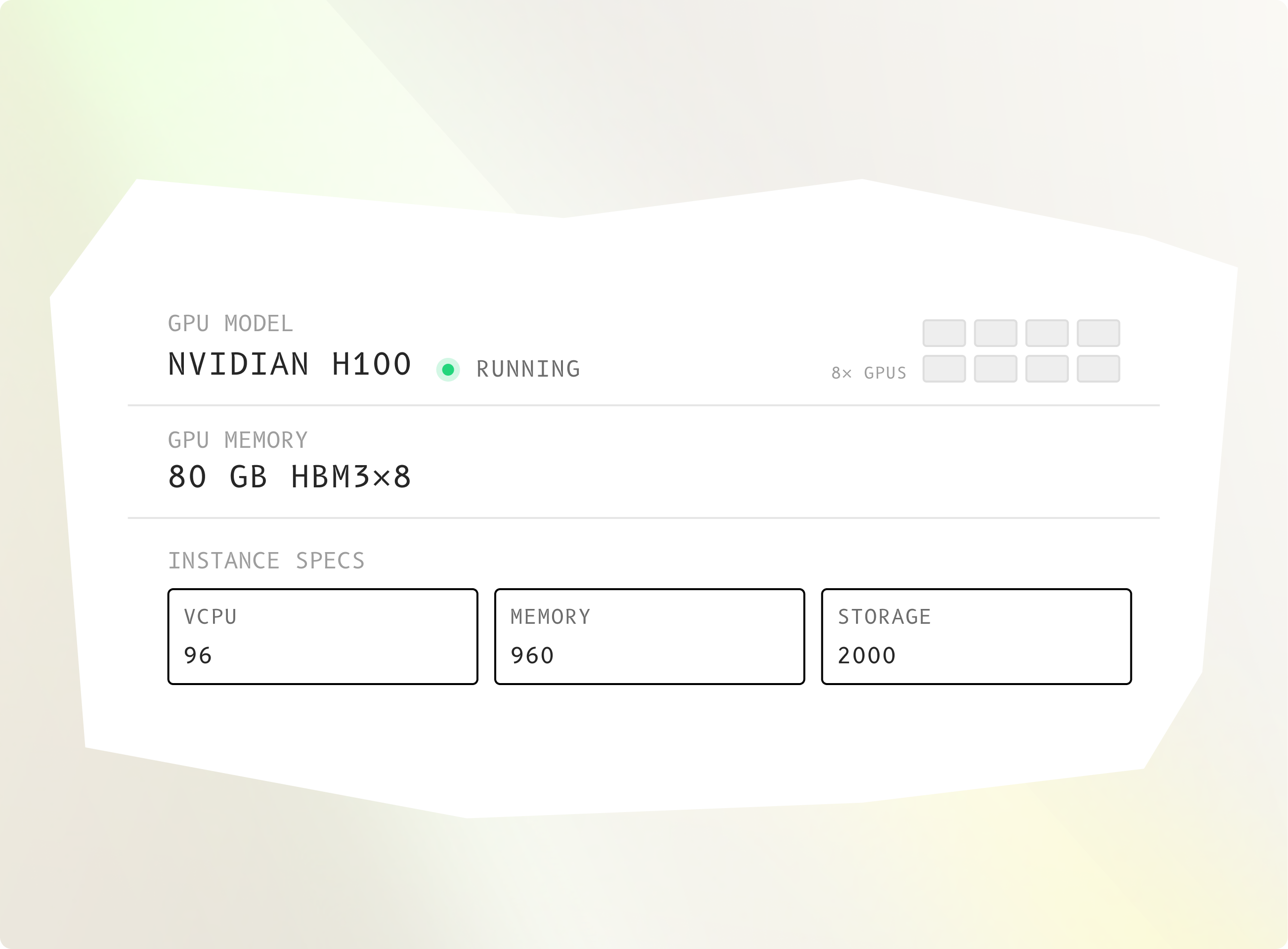
完全掌控的 GPU 机器。数秒即可拥有。
在你完全掌控的专用 GPU 实例上部署模型、运行推理、从零开始训练。性能可预测。无共享资源。无意外状况。
提交作业。其余交给我们。
无需预置实例。无需为闲置算力付费。Novita 会自动分配 GPU 资源,在负载增加时扩容,在任务完成后缩容至零。你只需为执行付费,别无其他。

allocating gpu resources
已分配
auto
时长
0.1s
成本
$0.0001
空闲时间
$0.00

Node-01
51%
Node-02
79%
Node-03
86%
Node-05
89%
Node-06
65%
Node-07
81%
GPU 8× NVIDIA H200
GPU Memory 141 GB HBM3e per GPU
Nodes 6 / 6
Interconnect NVLink 4th Gen · 900 GB/s
Network 400 Gb/s RDMA
极致性能。零抽象开销。
专用物理 GPU 集群,适用于大规模推理、训练运行以及不能在吞吐量上妥协的企业级部署。当你需要独占硬件时,这就是你的选择。
从第一天起就为 AI 而构建。专为你实际构建的内容而设计。
更优性价比
比主要云服务提供商最高低 50%。不是因为我们偷工减料,而是因为我们自建了基础设施。

为生产级可靠性而构建
稳定的基础设施,具备低延迟、高吞吐量和大规模可靠正常运行时间。
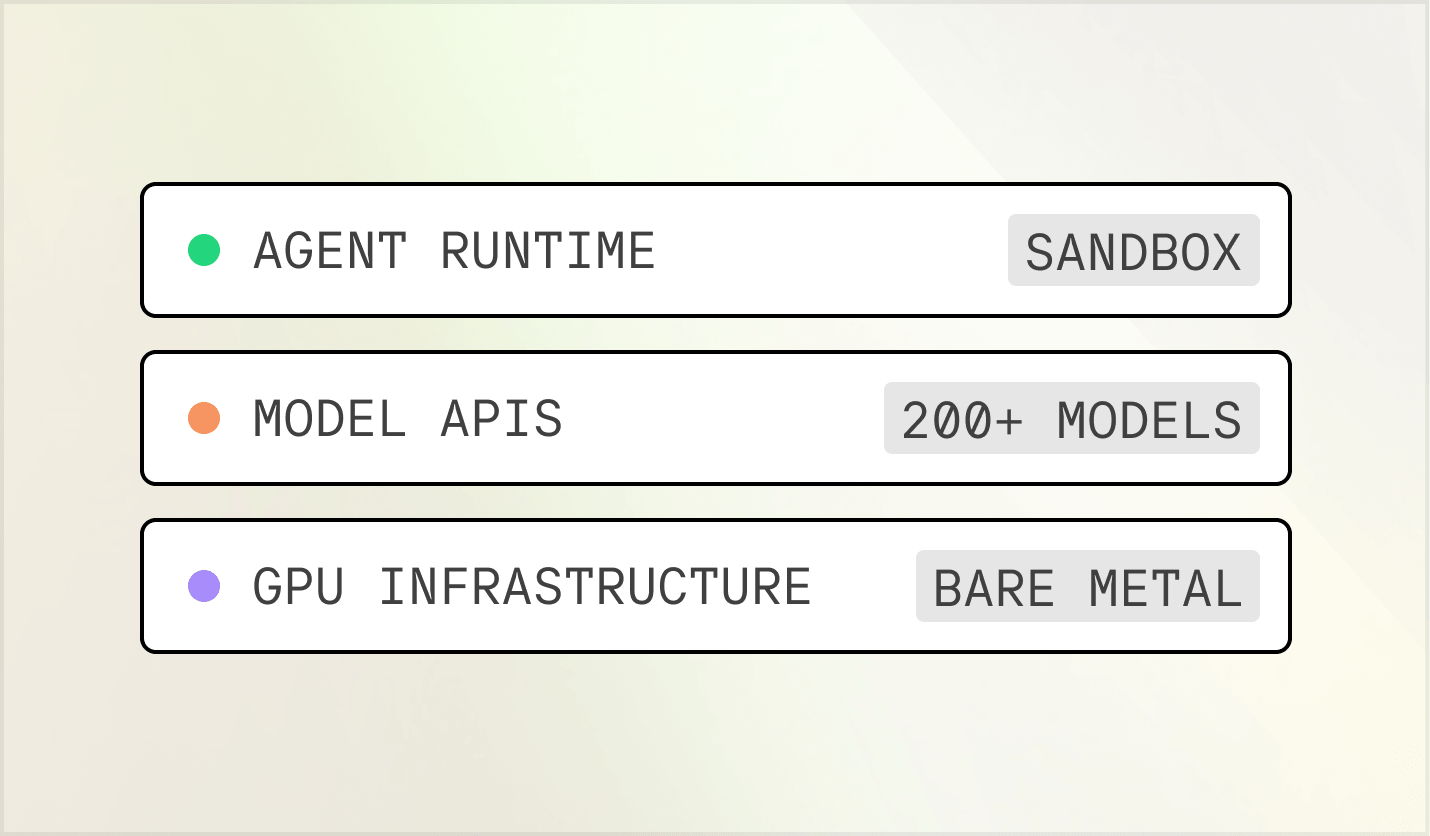
覆盖完整 AI 技术栈的一个平台
模型 APIs、GPU 基础设施和智能体运行时——全部集成于一个平台。
随工作负载扩展
从小规模开始,从 APIs 无缝扩展到专用集群。

在关键时刻提供专属支持
由深谙 AI 基础设施的团队提供快速技术支持。

Don't take our word for it.
我很欣赏 Novita AI 部署新发布模型的速度。他们的团队通常是最早将稳定、生产就绪的推理支持上线的团队之一,很多时候是在发布首日。这种速度对整个开源 AI 社区至关重要。

Julien Chaumond
联合创始人兼 CTO
Novita 对我们 Fish Audio 帮助巨大。他们可靠的 GPU 基础设施让我们能够专注于开发和改进我们的文本转语音模型,而不必处理硬件方面的麻烦。他们的支持和性能让我们更轻松地推动工作向前发展。

Shijia Liao
联合创始人兼首席科学家
Novita 的模型 API 集成起来非常简单,并且在驱动我们的 AI 闪卡和测验方面表现出色。该平台承担了繁重的工作,因此我们可以专注于为用户构建更好的学习工具,而无需担心基础设施或扩展问题。

Petros Christodoulou
联合创始人兼首席执行官
与 Novita AI 合作对 Kilo 来说是一次非常棒的体验。他们的推理平台帮助我们在多个 LLMs 上交付快速且可靠的 AI 编码工作流,并在智能体工作流的真实场景中展现出强大的性能。而且他们的团队非常易于合作!他们始终基于最新模型和技术进行优化——是 Kilo Code 的完美合作伙伴。

Ari Messer
合作伙伴关系负责人





构建生产级 AI 所需的一切。
200+ 个模型、按需 GPUs 和安全的智能体运行时——统一在一个 API 下。免费开始,随业务增长灵活扩展。